Proprietary Core Technology

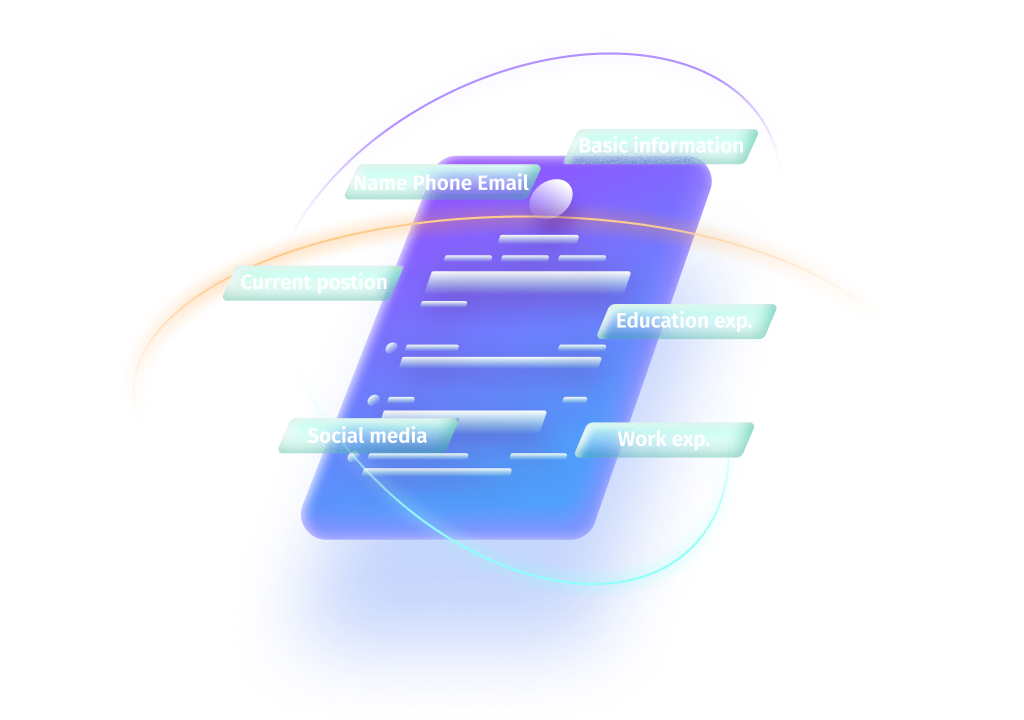
Resume Parsing
Based on our self-developed natural language understanding framework and layout analysis engine, combined with our unique recruitment knowledge graph, we significantly improve enterprise recruitment management efficiency.
Long-standing Pain Points, Solved in the Short Term
Campus Recruitment
Candidates spend a lot of time manually filling out resumes, resulting in a poor application experience.
Internal Referrals
The process of uploading resumes for employees is cumbersome, leading to low referral efficiency and poor candidate experience.
Regular Recruitment
Manual screening is time-consuming, and the system user experience is poor.
Recruitment Digitalization
Data structuring is the foundation of all digitalization work. The ability to structure talent data directly determines whether enterprise recruitment digitalization can proceed smoothly.
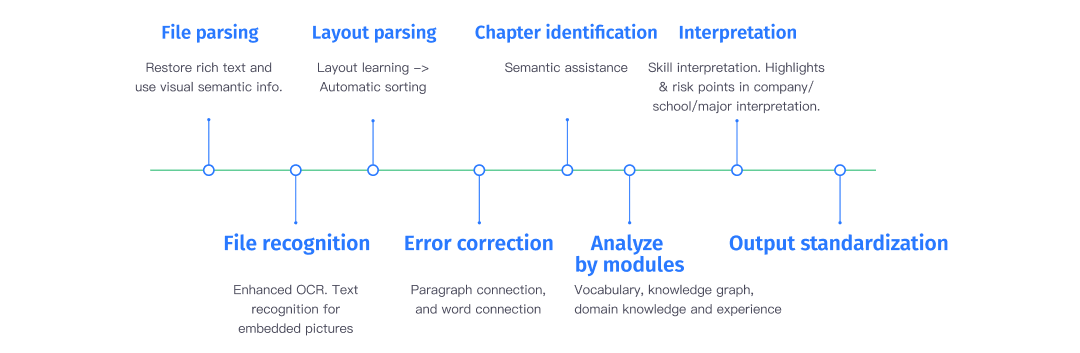
Core Processing Flow
The first step in talent data intelligence is to structure and standardize large amounts of unstructured, non-standard data, paving the way for subsequent labeling, conceptualization, and intelligence.
Resume Fingerprint Deduplication
Leveraging Bello's powerful resume parsing and knowledge graph technology, we create a unique fingerprint for each resume, helping companies eliminate duplicate resume purchases and repeated recommendations from headhunters, potentially saving hundreds of thousands to millions in expenses annually.

Multi-level Fingerprinting
Bello's resume deduplication is based on the principle of "multi-level fingerprinting," which comprehensively determines duplicates by combining different field contents to uniquely identify a person with varying levels of confidence. It also supports customizing deduplication strategy rules through configuration files.
Candidate and Job Profile Analysis
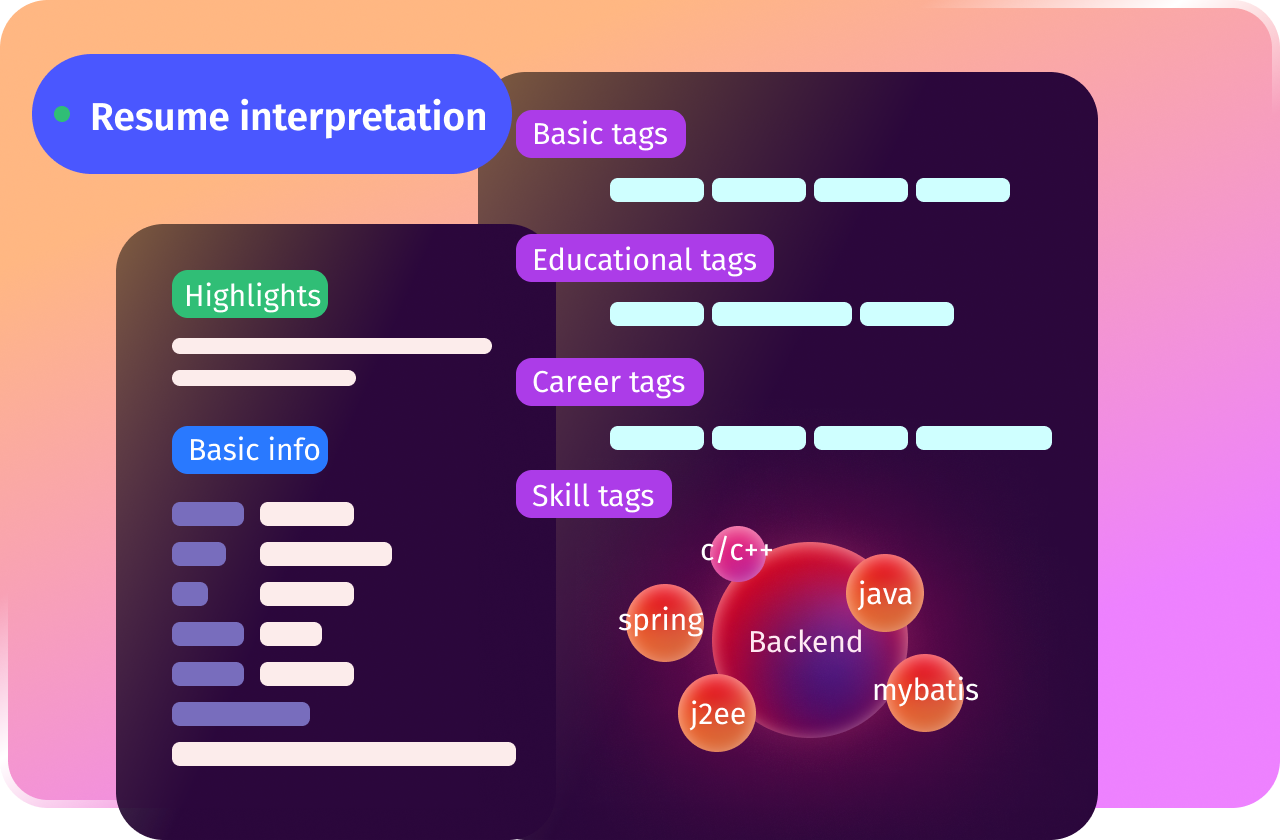
Talent Profile Tag Extraction
+ Professional Skills Data Visualization

Job Requirement Analysis and Tag Extraction
Knowledge and Concept Graph
Based on Large-scale Corpus
Bello uses hundreds of millions of anonymized resumes, tens of millions of job requirement data, and multiple tens of millions of open encyclopedia-type data sources as raw corpus. We preprocess this corpus using the EMR big data processing platform to ensure maximum coverage.
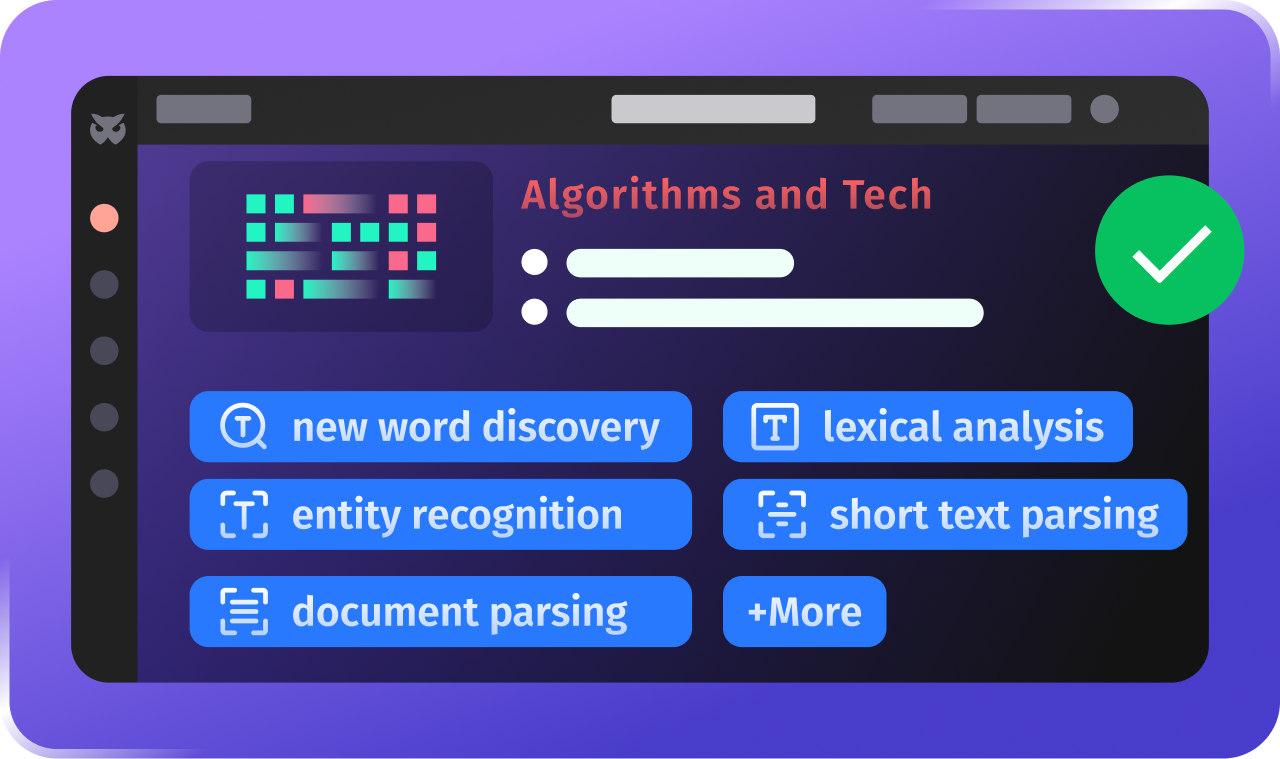
Domain-specific Preprocessing and NLP Foundational Technology
To fit the recruitment scenario, Bello has developed algorithms and technologies across multiple levels, from new word discovery, lexical analysis, and entity recognition to short text parsing and document parsing, enabling NLP to truly take root in the recruitment field.

Continuous Mining and Iterative Update Capability
While initially requiring significant investment from expert consultants to build the basic framework of the knowledge graph, we later combine pattern recognition, probabilistic graphical models, and other graph mining technologies to greatly improve graph construction efficiency, minimizing the cost of large-scale graph updates.

Few-shot Learning Capability
By slightly modifying our graph construction technology, we can achieve few-shot learning capabilities, solving the challenges of building graphs for niche positions or special functional roles.

Customer Manager
Articles
Unlocking New Horizons in Recruitment: Bello's Intelligent Job-Candidate Matching Helps You Recruit Efficiently. Looking to achieve efficient management? Bello's private deployment of human resources systems is here to give you a helping hand. Bello Human Resource System Integration Leads the New Trend of Intelligent ManagementContact Us


